
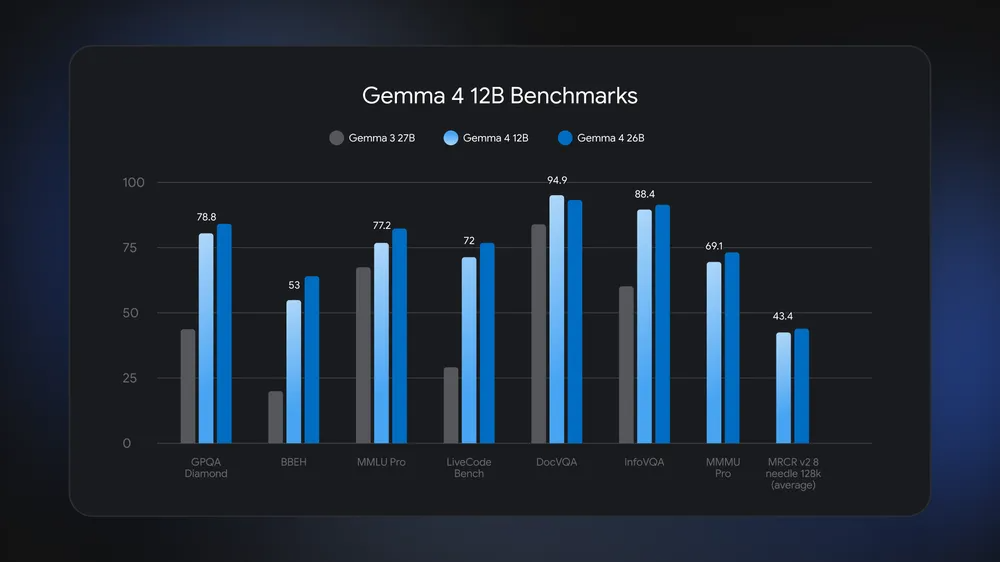
Gemma 4 12B is almost as capable as the version with 26 billion parameters.
Credit: Google
Gemma 4 12B is almost as capable as the version with 26 billion parameters. Credit: Google
Google says the new model is capable of complex multistep reasoning and agentic workflows that previously required the larger Gemma variants. Despite the smaller parameter count, Gemma 4 12B comes with the newly devised Multi-Token Prediction (MTP) drafters, which take advantage of unused processing cycles to calculate possible future tokens. The result is greater speed and efficiency. Google has released optional MTP versions of the other Gemma 4 models, but this is the first one to have MTP out of the box.
Gemma 4 12B is also more efficient thanks to a new approach to multimodality. The Gemma 4 family is natively multimodal, accepting text, audio, or images as inputs. Most gen AI models—including the other Gemma 4 variants—use dedicated encoders to process non-text inputs and pass that data to the LLM. This works well enough, but it increases latency and memory usage.
With the new mid-weight model, Google has implemented a streamlined embedding module for vision, featuring single-matrix multiplication and positional embedding, which allows the data to pass to the LLM with proper spatial awareness. This eliminates the need for a bulky middleman encoder. For audio, there’s no encoding at all. The developers worked out a method of projecting the raw audio signal into the same vectors used for text tokens.
If you want to check out the new Gemma 4 model, it’s accessible without a download via tools like LM Studio, Google AI Edge Gallery, and more. But the whole idea with Gemma 4 12B is that you can run it locally and on your own terms. If you’ve got the RAM, the model weights are available for download immediately on Kaggle and Hugging Face. It’s just shy of 18GB.