Samsung Electronics brings ChatGPT and Codex to employees
Samsung Electronics deploys ChatGPT Enterprise and Codex to employees worldwide, marking one of OpenAI’s largest enterprise AI rollouts.
AI/ML news, top picks, and generated innovation digests.
8303 matching items
Samsung Electronics deploys ChatGPT Enterprise and Codex to employees worldwide, marking one of OpenAI’s largest enterprise AI rollouts.
Temporary Cloudflare Accounts for AI agents The announcement says this is "for AI agents" but (as is pretty common these days) the AI hook isn't really necessary, this is an interesting feature for everyone else as well. Short version: you can now create a Cloudflare Workers project and run this, without even creating a Cloudflare account: npx wrangler deploy --temporary Cloudflare will deploy the application to a new, ephemeral project which will stay live for 60 minutes. I had GPT-5.5 xhigh in Codex Desktop build this test application providing a tool for following HTTP redirects and returning the final destination. The temporary deployment worked as advertised. Running the deployment spits out the URL to a page for claiming the new project, for if you want it to last for more than 60 minutes. Here's what that claim screen looks like: Via Hacker News Tags: cloudflare
PLUS: Claude robotics, Dean Ball at OpenAI, DeepSeek's raise, and sovereign models.
special offer for subscribers - $250 off AI Engineer tix til Monday
2026-2030 'AI for all' roadmap targets health and farming, schools
Comparing the US and China Transmission Buildout
YouCode school targets talented school dropouts, aiming for 100 trainees a year
On the world stage, Canada's prime minister is a statesman. In Ottawa, he is a ward boss.
A sandboxed target, inputs that influence task difficulty, tools, and a grader.
Authors: Joshua Engels*, Callum McDougall*, Bilal Chughtai*, Janos Kramar, Senthoran Rajamanoharan, Cindy Wu, Arthur Conmy, Asic Q Chen, Jean Tarbouriech, Min Ma, Brendan O'Donoghue+, João Gabriel Lopes de Oliveira+, Rohin Shah+, Neel Nanda+ *Primary Contributor +Advising Paper here: https://arxiv.org/abs/2606.20560 Overview In a recent collaboration between the GDM interpretability team and the GDM text diffusion team, we performed a transparency audit of DiffusionGemma, GDM's new text diffusion model. Overall, we find that DiffusionGemma is not significantly less transparent than Gemma. Gemma and DiffusionGemma perform similarly on monitorability evaluations . Although naively DiffusionGemma has a much larger opaque serial depth , we can apply the logit lens to intermediate vectors and ablate non-interpretable information without harming performance. This implies that these intermediate nodes are interpretable, which reduces the opaque serial depth to be similar to that of Gemma. However, even though the variables that the model uses at different steps are interpretable, this does not necessarily mean that we understand the algorithm that the model uses to reach the final answer. We thus distinguish between variable transparency, which we define as whether we can understand snapshots of the model's computation, and algorithmic transparency, which we define as whether we can use these snapshots to reconstruct the process by which the model arrived at its outputs. By default…
The aviation agency has partnered with tech company Palantir. “The long-term goal is to get to predictive,” said one official.

Salome Mikadze-Struk is no stranger to adversity. The daughter of refugees, she built a software-development business as an undergraduate at the height of the COVID-19 pandemic and kept it running despite the outbreak of war in her native Ukraine . Now, she’s drawing on her experiences to mentor tech-startup founders and speak publicly about the importance of resilience in entrepreneurship . Mikadze-Struk was studying at Georgetown University, in Washington, D.C., when COVID-19 struck. Classes went online, and she moved back to Ukraine. In the midst of that disruption she saw an opportunity to develop her business idea, called Movadex , by tapping Ukraine’s pool of talented young engineers. Then Russia invaded in early 2022, during her final semester. Taking online classes from bomb shelters and helping employees evacuate to safer parts of the country was surreal, she says, but the team kept the company afloat and she graduated later that year. In 2023, Mikadze-Struk took a hiatus from her business to pursue an MBA at Stanford University, which she completed this year. In her precious spare time she’s been advising startups and giving talks, using her unique perspective to promote the need for resilience in entrepreneurship—something she thinks is increasingly important in the software industry as AI coding tools upend old business models. “You need to be okay with risk, you need to be resilient. You need to be okay with disruption and okay with uncertainty,” she says, “beca…
it's pretty well known that there are issues with initialization and dealing with non-stationarity of resulting estimates etc. But, for this question, one can assume that all these things are taken care of in the algorithm. So, my question is : can the resulting parameter estimates be thought of as those that minimize the one step ahead forecast error of the respective arima model ? Mathematically, any algorithm is maximizing a likelihood, but that likelihood is a function of the estimated residuals so it still feels like one is capturing the best one step ahead forecast ? Thanks for any insights or references ? This question came to my mind recently when I realized that I'm not really interested in the one step ahead forecast.
But So Are Converters, Inverters, and MMCs!
In an administration that rewards political deference, Anthropic’s CEO has repeatedly clashed with the White House.
Inside Kyiv’s secret drone program that’s hitting targets deep inside Russia.
a quiet day lets us promo AIE one last time
By Celina Amados At Netflix, our catalog metadata is crucial to our member experience, and a single corrupted data state can impact millions of viewers immediately. To protect streaming reliability, we built an automated data canary system that validates data transformations using production traffic. This canary detects issues in under 10 minutes, and blocks bad data from reaching our members. Intro Catalog metadata is what makes Netflix functional. It defines what titles exist, where they’re available, whether they can be played, and more. This data gets transformed and distributed across our vast infrastructure near-continuously, powering everything that helps members find what they want to watch. Accurate catalog data delivers moments of joy. Corrupted catalog data breaks streaming. What Went Wrong A production incident revealed a critical gap in our resilience strategy. No code had been deployed. No configuration had changed. But, a manual mitigation action taken during a previous incident had inadvertently corrupted a data feed, rendering it empty for a subset of titles. The impact was immediate: missing metadata prevented manifest generation, causing failures in our catalog service and playback issues. Engineers were alerted immediately, but identifying the root cause took time. After intense triaging, responders pinpointed the corrupted data feed and pinned services back to a known-good state, restoring playback. The problem? Our sophisticated code canary deployments…
By Amer Hesson , Marcelo Mayworm , James Mulcahy , and Brittany Truong The Problem: Managing Assets at Netflix Scale Netflix’s Data Platform is vast. We have millions of tables in our data warehouse and tens of thousands of scheduled workloads running across our orchestration systems. Behind each of these assets sits an engineer, a team, or an initiative — and behind each of those sits a set of decisions about who can access what , and how those workloads execute day after day. For years, the tools we used to manage access and identity for these assets operated at the granularity of the individual asset. Every table had its own Access Control List (ACL). Every workflow ran under the identity of the engineer who authored it. In a workforce that is fluid, where people change teams, change roles, and occasionally leave the company, this fine-grained model broke down in two persistent, painful ways. Problem 1: Permissions that can’t keep up with organizational changes Imagine you’re on a team that owns a few hundred tables. Your org restructures, a neighboring team merges into yours, and you inherit another few hundred. Now you have to find every ACL on every table, figure out who should still have access, and update them one by one. Multiply that by every reorg across every team across the company. The result? Two failure modes: The support team gets flooded. A significant and outsized share of support threads were requests to update table permissions en masse in response to or…
by Emily Gill Each year, we bring the Analytics Engineering community together for an Analytics Summit — a multi-day internal conference to share analytical deliverables across Netflix, discuss analytic practice, and build relationships within the community. This post is one of several topics presented at the Summit highlighting the breadth and impact of Analytics work across different areas of the business. Understanding Risk in Content Launches Every title you see on Netflix goes through several key phases: Development, Pre-Production, Production/Principal Photography, Post-Production, and finally, Launch Preparation, all leading up to the Title Launch. Once Principal Photography wraps, the focus shifts in Post-Production from content creation to quality assurance and visual effects (if needed). At the end of Post Production, Netflix receives the final audio and video files — often delivered as an IMF (Interoperable Master Format) — which triggers a flurry of Launch Preparation activities, focused on tasks such as the development of artwork and trailers, creation of subtitles, maturity ratings & quality control, that happen within a tight window and rely on having the finalized media assets in hand. Some of this work can be kicked off earlier using a non-final version of the media called the Locked Cut, but since it’s not the absolute final deliverable, this presents a tradeoff: should our teams who prepare content for service wait for the more finalized IMF to begin their…
By Guil Pires , Jennifer Prince , Jose Camacho , Ken Kurzweil , Phanindra Chunduru Background In a previous post, we introduced Data Bridge , a unified management plane for batch Data Movement at Netflix. Historically, several bespoke Data Movement connectors were developed across different engineering organizations to fulfill their specific requirements. Over the last few years, the Data Movement team has started centralizing these offerings through an abstraction that provides a catalog of connectors, along with simple UI and APIs to initiate Data Movement jobs. One such case is the Cassandra to Iceberg connector. Apache Cassandra powers mission critical applications at Netflix, including Member, Billing, Recommendations, Subscriptions and many more. These use cases heavily leverage Data Movement to Apache Iceberg for many analytics and operational tasks, and central to this movement was a connector for Cassandra to Iceberg built in-house named Casspactor. As many Cassandra based Data Abstractions emerged, such as Key Value , Time Series and Graph — the need for larger and more complex Data Movement with transformations became more critical to the business. Data movements are fundamentally fulfilled by leveraging the existing Cassandra backup infrastructure. Regularly scheduled backups are performed directly on the Apache Cassandra nodes, via a sidecar process managing the upload of all necessary SSTables and associated Metadata files directly into Amazon S3. When a Data M…
by Matthew Wood , Ishan Gupta , Kevin Mercurio, Devon Bryant , and Claire Dorman In his seminal book “Thinking, Fast and Slow,” Daniel Kahneman describes two systems that drive human cognition: System 1, which operates automatically and quickly with little effort, and System 2, which allocates attention to more challenging mental activities requiring deliberate focus. This dual-process theory has profound implications not just for understanding human behavior, but for designing intelligent systems that must balance immediate responsiveness with strategic foresight. Similar “plan vs. act” decompositions show up in other domains too — for example, robotics and autonomous driving often separate a slower planning layer (setting goals and constraints over longer horizons) from faster control and execution loops, and modern LLM agents frequently pair deliberate planning with rapid, step-by-step tool use and reaction. At Netflix, our messaging platform faces a similar challenge every day. We send hundreds of millions of personalized notifications — push messages, emails, and in-app alerts — to help members discover content they’ll love. This creates a central tension: optimizing each notification for near-term engagement can conflict with what is best for the member over the long term. Higher message frequency can increase fatigue and opt-out risk, while lower frequency can reduce awareness of relevant titles and features the member would value. This blog post introduces our framew…
By Winston Chou, Adrien Alexandre, Lars Olds, Yi Zhang, Garrett Hagemann, and Nathan Kallus Introduction Imagine asking a data agent to analyze the causal relationship between two variables, such as the effect of watching a popular Netflix show on long-term member retention. It queries your data, runs a regression, and confidently returns an answer. How much should you trust it? Can you be confident that the agent accounted for subtle biases — or does it treat passionate fans as if they were the average viewer? Without deep understanding and expertise, would you even be able to tell if it got the answer wrong? Data analysis is increasingly being delegated to software agents. While this reduces human effort and toil, oversight is still needed to ensure the validity of results. This is especially true for specialized tasks like Observational Causal Inference (OCI) , which require substantial judgment and domain expertise. In this blog post, we share an agentic workflow for performing OCI under unconfoundedness . Our workflow is designed for software agents to adhere to rigorous, exhaustive templates for causal inference tasks. Yet, it also seeks to be “ human-augmenting ,” and to enable and empower human inspection and evaluation. We designed this workflow with OCI practitioners in mind. Although OCI requires context and care to do well, aspects of it — e.g., checking and rechecking covariate balance, conducting sensitivity analyses, and keeping track of multiple iterations —…
By Parth Jain , Rakesh Sukumar , Yingwu Zhao , Renzo Sanchez-Silva & Nathan Fisher How we built a living map of our distributed infrastructure to help engineers understand dependencies, troubleshoot faster, and keep Netflix running smoothly for our members around the world. The Puzzle with a Thousand Pieces Picture this: It’s 3am, and an engineer gets paged. One of our critical services is showing elevated error rates. Members trying to watch their favorite films and series are seeing degraded experiences. The clock is ticking. A single service at the center of a web of dependencies — services, data stores, and call chains branching in every direction. Without a unified map, engineers have to reason about this structure from memory and scattered signals. In a system with thousands of microservices supporting our entertainment experience for members worldwide, answering these questions quickly can mean the difference between a minor blip and a major incident. We kept hearing variations of this story from engineers across Netflix. The tooling gap was clear: we had plenty of signals, but no unified way to understand how everything connected. The Three Questions Every Engineer Asks When troubleshooting distributed systems, engineers fundamentally need to understand relationships: Which services depend on each other? Not just theoretical dependencies from configuration files or architecture diagrams, but actual runtime connections based on real traffic. What’s the blast radius? W…

After introducing Codex, it grew to more than 10,000 active users and became one of the largest internal community in just a few months." We chatted with Hiroaki Sato, Head of the AI CoE at NTT DATA who gave us insight into all of the new ways his technical and non-tech teams are leveraging Codex. His Sales teams uses Codex to automate tasks like customer list maintenance, which has created net new workflows and report creation that used to take 2 days now takes 30 min 💥
The real valuable capability MCP offers over skills/CLI is isolating the auth flow outside of the agent’s context window, and potentially out of the harness completely. [...] Maybe the idealized form of MCP is just an auth gateway for the API and nothing else. That’d still be a win. — Sean Lynch , comment on Hacker News Tags: model-context-protocol , llms , ai , generative-ai , skills


By Adam Wolf Running production LLM inference on a new accelerator family is a layered problem. The model matters. The runtime that exists for the GPU you have matters at least as much. So does the precision mode that works without losing accuracy, the inference engine that hits your throughput targets, and the secure endpoint […]
Appearing at the Big Technology AI Summit Thursday, OpenAI president Greg Brockman indicated that winning the compute race could be the key to winning more broadly.

Large language models have moved out of the research lab and into engineers’ daily workflow. LLMs serve as reasoning engines that can orchestrate complex tasks including identifying vulnerabilities in source code and transforming fragmented project discussions into rigorous technical specifications. While the general public uses AI tools to write email and plan vacations, technical professionals use LLMs as core architectural elements that are fundamentally changing how digital infrastructures are built and maintained. As the AI models move into mainstream engineering practice, the demand for technical expertise is rising. The LLM technology market is expected to grow by about 33 percent every year through 2030 , according to MarketsandMarkets . The rapid expansion suggests that proficiency in implementing and securing the models is transitioning from a niche into a core requirement for technologists. More than just a better search engine To use LLMs effectively, technical professionals must move beyond treating them as conversational robots. At a fundamental level, the AI systems are built on the transformer architecture , a framework that replaced the older method of processing data in a fixed, sequential order. Unlike earlier models that analyzed information one step at a time, transformers use self-attention mechanisms to ingest vast datasets simultaneously. For technical professionals, LLMs are core architectural elements that are fundamentally changing how digital infr…
Qubot, our internal Copilot-powered analytics agent, allows any GitHub employee to ask questions about our data in plain language. Here's what we learned as we built it. The post How we built an internal data analytics agent appeared first on The GitHub Blog .
ML system design interviews test how well you can think beyond models. In these interviews, choosing an algorithm is only one part of the answer. You also need to explain how data is collected, how features are created, how predictions are served, and how the system improves over time. Most real ML systems are built […] The post System Design for ML Interviews: 10 Real Problems Walked Through appeared first on Analytics Vidhya .

Web Search on Amazon Bedrock AgentCore is now generally available. In this post, we walk through what makes Web Search on Amazon Bedrock AgentCore different, why it matters, and how to wire it in with a few lines of code.

❤️ Check out Weights & Biases and sign up for a free demo here: https://wandb.me/papers 📝 The paper is available here: https://recursivemas.github.io/ https://github.com/RecursiveMAS/RecursiveMAS Brain reading video: https://www.youtube.com/watch?v=IUg-t609byg 🙏 We would like to thank our generous Patreon supporters who make Two Minute Papers possible: Adam Bridges, Benji Rabhan, B Shang, Cameron Navor, Charles Ian Norman Venn, Christian Ahlin, Eric T, Fred R, Gordon Child, Juan Benet, Michael Tedder, Owen Skarpness, Richard Sundvall, Ryan Stankye, Shawn Becker, Steef, Taras Bobrovytsky, Tazaur Sagenclaw, Tybie Fitzhugh, Ueli Gallizzi
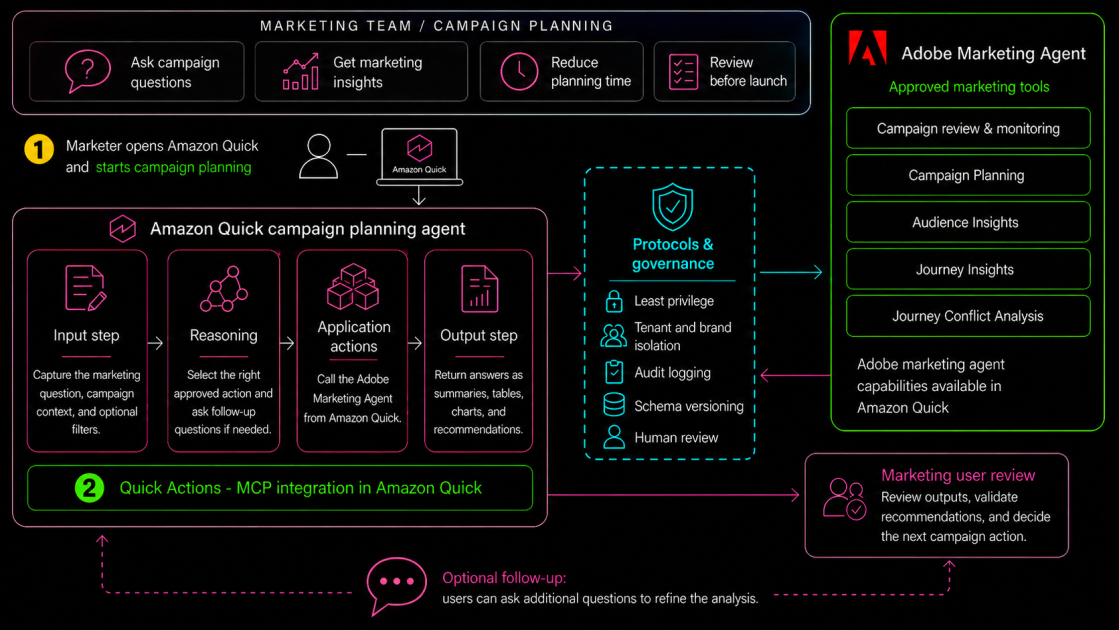
This post shows how to enable Adobe Marketing Agent for Amazon Quick using a Model Context Protocol (MCP). We walk you through how to configure the integration, authenticate using your Adobe credentials, and get the latest insights in Amazon Quick. The sample workflow returns audience rankings, loyalty segment summaries, journey usage, and conflict recommendations.

SAP and Google Cloud are deploying agentic commerce architecture to automate multi-agent marketing and retail operations at enterprise scale. SAP research indicates 78 percent of businesses consider AI essential for retaining customers in 2026. However, the same data reveals fewer than two in five companies share customer data across customer experience (37%) or CRM (39%) […] The post SAP and Google Cloud deploy agentic commerce architecture appeared first on AI News .
Token spend does not prove AI is creating value. Teams need cost-per-outcome metrics that connect AI usage to resolved tickets, accepted code, shipped features, and other business results. The post Why AI token costs don’t tell you if your AI is working appeared first on Arize AI .
Designing contract-bound AI agents for high-stakes execution.
I am building a production-grade recommendation system for a short-video platform (processing around 50k videos). The architecture utilizes a vector database ( Qdrant ) to store and query 768-dimensional video embeddings generated by a VideoCLIP model. To track user preferences in real-time, I implement an online learning mechanism that updates a single user_vector iteratively after each interaction based on a computed rating (bounded between [-1.0, 1.0] via tanh ). The Goal & The Problem I want my system to actively update the user vector on both positive and negative signals . Initially, I tried a standard linear combination: updated_vector = (alpha * u) + (beta * v * rating) Where u is the current user vector, v is the video vector, alpha is the decay, and beta is the learning rate. However, when a user gives a negative rating (e.g., -0.8 ), multiplying the VideoCLIP embedding by a negative scalar flips its direction entirely. In a 768-d multimodal space, adding this inverted vector creates massive noise across unrelated dimensions, causing aggressive vector drift instead of just moving away from that specific topic. On the other hand, simply clamping negative ratings to 0 fixes the geometry but creates a severe feedback loop/frozen vector issue where the profile stops evolving during consecutive negative interactions. What I Want to Achieve I need a mathematically sound way to update the vector during negative interactions so that the user profile actively flees from the…

In healthcare settings where patients use LLMs as a medical assistant, LLM performance differs between evaluation and deployment. (a) Bean et al. (2025) find a 61 percentage point difference between evaluation and deployment. (b) We argue this gap arises not from poorly designed benchmarks, but from implicit assumptions embedded in evaluation protocols that fail to hold at deployment. (c) We propose a taxonomy that categorizes assumptions into two types, task and outcome, to diagnose where the gap arises and what is required to close it. Closing the gap requires making assumptions explicit, testing which assumptions hold, and updating evaluation protocols accordingly. Healthcare LLM benchmarks are one of the main paradigms by which LLMs are evaluated prior to clinical settings. Benchmarks provide a stable goalpost that allow researchers to iterate quickly and measure progress consistently. However, in high-stakes domains like healthcare, that same abstraction becomes a liability. For example, a recent study found a 61 percentage point drop in accuracy when going from evaluation to deployment (see Figure). In this setting, patients use LLMs as a medical assistant to better understand their symptoms, identify the underlying condition, and take appropriate actions. Moreover, the results showed that patients given access to a […]
This post was originally an op-ed co-authored with Kevin Xu of Interconnected for a general, non-technical audience.
The moment an agent needs to deploy something, it slams face-first into a wall built for humans. Today we're rolling out Temporary Accounts on Cloudflare Workers. Any agent can now run wrangler deploy — temporary and get a live Worker in seconds.
The Dutch East India company was among the first modern companies to receive legal personhood. Should we reconsider what personhood means in the age of AI?

“My ‘Skill’ is uploaded; my cubicle has been emptied.”
The Advisory Forum (the Forum) is a general advisory body to the European Commission and the AI Board, established to provide technical expertise, advise them, and to contribute to their tasks under the EU AI Act. It sits within the Act’s broader governance architecture, as one of the two advisory bodies, in addition to the […]
PLUS: A reasoning model helped doctors surface 18 confirmed rare-disease diagnoses.

In 2018, Amazon brought me in as the lead UX Sound Designer for Astro, its first consumer home robot . Astro used cameras and other sensors to map and navigate your home and workplace , and could proactively patrol, check up on loved ones, and transport small items using its built-in cargo bin. While there was a well-defined feature set and form factor, initially there was no character direction. In fact, even before Astro had a name, there were two main questions—was it simply Alexa on wheels, or was it a robot with its own character? The Astro team was divided. One option was to focus on Alexa, and treat the mobile robot simply as an added utility. Along with the majority of the UX team, I argued for Astro to not focus on Alexa. Our belief was that a thing that moves through your home and turns toward you with intent can never be just an appliance. People would ascribe character to it whether we wanted them to or not, and so the only question was whether we shaped that character or let it happen by accident. Ultimately, Astro became Astro rather than Alexa , and user testing backed up our decision. People didn’t see the robot as Alexa. They saw it as its own character, and that’s what they wanted it to be. Alexa on the device felt somewhat strange and creepy, but building Astro its own voice was too slow and expensive in 2018. So, we settled on Alexa as a supporting character that handled any actual talking, while Astro was the main character, communicating as much as it c…