
Plane crash in Beijing reveals airspace security gaps
A small plane crash in China’s capital exposed major gaps in the country’s airspace controls, analysts said, as the government tried to limit public discussion of the incident.
AI/ML news, top picks, and generated innovation digests.
7350 matching items
A small plane crash in China’s capital exposed major gaps in the country’s airspace controls, analysts said, as the government tried to limit public discussion of the incident.

Tehran attacked American military sites in Kuwait and Bahrain after the US accused Iran of attacking a cargo ship in the Strait of Hormuz and targeted Iranian infrastructure in response.
Human Agent in the loop I dislike the phrase “human in the loop” because it cedes authority to the machines. Let’s flip the narrative. It’s our loop, we work the same way we always have, now we recruit agents to join the team. An agent-assisted process need not be a black box that takes in prompts and emits features. [...] Let’s do agentic software development like that. Not as a loop we’ve been excluded from, instead as one we invite agents into. — Jon Udell , “Doctor, it hurts when agents create unreviewable PRs.” “Don’t do that.” Tags: jon-udell , coding-agents , generative-ai , agentic-engineering , ai , llms

Arab League condemns continued Iranian attacks on Bahrain, Kuwait
China's Zhipu AI (Z.ai) released its open-weight GLM-5.2, and some researchers have claimed that it matches Mythos in certain bug-finding and cybersecurity scenarios. While GLM lags behind models from Anthropic and OpenAI in other, more general tasks, it seems that China has dramatically reduced the gap in the capabilities between its models and those of […]
Streaming ads might be getting a lot quieter.

I don’t want to have to keep creating new topics about this @OpenAI_Support please let me know of any updates, i still have not received any response in almost a month since it was escalated to a “Specialized Team” and I haven’t gotten any updates here. Is anyone still looking at my case or what is happening?

Among those attending are Belgian Prime Minister Bart de Wever, NATO Secretary General Mark Rutte, and European Parliament President Roberta Metsola.
the latest app version: Frequently crashes CLI chats / instance are not synced with UI, CLI chat do not appear in the app unable to transcribe furthermore, for remote control, the one QR code per account is useless feature if you have multiple accounts due to rate limits. so when one account is out of limit and you switch to antoher account you have to reset up your remote control in the app. account 1 sign in - get codex coding, sign in to remote control using QR code, runs out of limit, switch to account two, now need to resign in to use remote control with new QR code.

Spanish and international rescue teams pulled a survivor from the rubble four days after deadly earthquakes struck Venezuela. Search operations continue as crews race to find more survivors, with the death toll rising to more than 1,400.

Andy Burnham’s choice of chancellor will be the clearest signal of the direction he is planning on taking the country as a whole.
Suno has ambitions to be more than just a toy to churn out AI slop, it also wants to be a streaming destination and to break new artists. Spark is their new incubator program for independent artists that provides grants, mentorship, and marketing support. To apply, artists need to be an unsigned singer, songwriter, or […]
All right this is getting ridiculous . 3 weeks I am getting messages that support is looking into this but solution is still not provided, can someone write to me what is the issue and can we get this resolved finally??
A family trip with my four teenage and young adult sons reminded me how little time we have left before the nest empties.
I wonder if this is related to the new version of GPT-5.5 Instant released last week. Can anyone from OpenAI confirm whether Apps on Instant have a smaller effective context or tool-descriptor budget? I saw docs implying context size for Instant is now 16K tokens (and it used to be 27K tokens). Specifically, can large MCP tools/list payloads - descriptions, input/output schemas, annotations, metadata, etc. - cause exposed tools to become unavailable or stop being selected after an initial tool call?
Thanks to conversations with Anson Berns, Gurkenglass, Roman Malov, Sahil, Sam Eisenstat, and others. Over the past two months, I've been doing a lot of "vibe research" (like vibe coding, but for research). Anson Berns started coming to my office hours , and we've been collaborating on a project modeling trust between logical inductors. In addition to talking once a week, we've been exchanging raw AI chats as well as AI-generated summaries of what has been done (the raw chats are nice because they allow me to generate my own AI summaries focusing on what I'm most curious about). I've been asking Claude to use Lean to verify everything, so there's a somewhat good chance there's real results of interest here, but I haven't (yet) been reading the Lean proofs (or even the theorem statements) -- instead I've just been chatting with AI about how the Lean proofs went and whether they really formalized what was claimed in english+latex, and focused on understanding the proofs myself in the same way I'd normally read a math paper. There have already been several times when this methodology has caught big gaps between what was claimed and what was verified in Lean, so I imagine there are more. This was mostly done with Claude Opus 4.8 via Claude Code, with a small amount of GPT 5.5 Extra High in Codex to get a second opinion. I cannot confidently say that this was faster than doing research the old-fashioned way. Sitting down with AI puts my attention in very different places, more on…
This is a crosspost of a post from my blog, Metal Ivy . The original is here: Reinforcement Learning on Forecasting Will Give Us a Superhuman Forecaster . Why RL on forecasting? When DeepSeek R1 came out in January 2025, I felt that the fact that RL on LLMs simply worked was incredible, but using it on coding and math wasn’t the right path. Before RL we had pretraining, a scalable and general training methodology that worked extremely well to get the model to the human level, through learning by imitation over human data. Then RL came in and gave us a way to get even further, to the expert level and beyond, through sampling many trajectories from the LLM and using a reward function to select the best ones to reinforce. But it isn’t general anymore when only short term, self contained verifiable tasks such as coding or math make up the environment. A strongly superhuman coder might change everything - if recursive self improvement happens like the labs hope (and doesn’t kill us). But it might not change that much at all by itself, beyond giving us more of the software abundance we in many ways already have. A strongly superhuman forecaster instantly gives people and organizations the ability to make superhuman decisions through forecasting of their outcomes, and would be a massive boost to the overall competence of our civilization. You may ask why should it work, even in theory - math is deterministic and forecasting is not, so forecasting reward may give bad weight updates.…
This is a crosspost of a post from my blog, Metal Ivy . The original is here: Reinforcement Learning on Forecasting Will Give Us a Superhuman Forecaster . Why RL on forecasting? When DeepSeek R1 came out in January 2025, I felt that the fact that RL on LLMs simply worked was incredible, but using it on coding and math wasn’t the right path. Before RL we had pretraining, a scalable and general training methodology that worked extremely well to get the model to the human level, through learning by imitation over human data. Then RL came in and gave us a way to get even further, to the expert level and beyond, through sampling many trajectories from the LLM and using a reward function to select the best ones to reinforce. But it isn’t general anymore when only short term, self contained verifiable tasks such as coding or math make up the environment. A strongly superhuman coder might change everything - if recursive self improvement happens like the labs hope (and doesn’t kill us). But it might not change that much at all by itself, beyond giving us more of the software abundance we in many ways already have. A strongly superhuman forecaster instantly gives people and organizations the ability to make superhuman decisions through forecasting of their outcomes, and would be a massive boost to the overall competence of our civilization. You may ask why should it work, even in theory - math is deterministic and forecasting is not, so forecasting reward may give bad weight updates.…

The timing on this couldn’t be better. I run agentic systems daily - OpenClaw, Hermes, Claude Code orchestrating multiple AI workers. The bottleneck has always been cost at scale. Anthropic’s API pricing makes it brutal to run agents 24/7. You’re watching credits evaporate in real time. The fact that OpenAI allows third-party harnesses to tap into these models through an existing subscription changes the math completely. Looking forward to Sol Ultra powering my agents without per-token anxiety. And “Ultra” mode with subagents working together - that’s exactly where agentic AI needs to go. Thank you for making this accessible to builders, not just enterprises with infinite API budgets. Time to put these through their paces. I’ve got 6 DGX Sparks running great local model like Gemma4 and these 5.6 models are going to run it all.
Hack Your Summer I learned about this initiative from DJ Patil this morning: It’s a 4-week, high-velocity production sprint for undergraduate students, graduate students, and recent graduates who want to build something real this summer. You’ll learn how to identify a project, make steady progress, get support from mentors and peers, and create tangible, public-facing work you can actually show future employers. Hack Your Summer is partly a reaction to the internship crisis facing US college students this year. There are way fewer available internships than usual, as companies have reduced their hiring ambitions and teams have less capacity to coach interns. Hack Your Summer provides an alternative path for the many students who didn't catch one of those rare internships. A second (free) cohort starts on July 13th, and the deadline for students to apply is July 8th. They're also accepting volunteers to help mentor the students. Tags: careers

When cricket broke hearts, hockey gave India a reason to smile

The IRGC said the weekend US strikes violated the framework deal and warned that violating vessels would face a "crushing response," as Euronews journalists in Doha observed US refuelling aircraft taking off towards Hormuz in the same formation as the previous night's strikes.
I wrote a fairly accessible introduction to real hypercomputation with Marcus Hutter. The focus is on enabling applications to algorithmic information theory. This project was intended to build my technical foundations for studying AIXI, but took me a bit further afield and down some rabbit holes. In the future I will prefer to focus more tightly on AI safety. Feedback would be appreciated. In particular, I needed to introduce an extra extensionality assumption for the real domain case, which I am still not sure is necessary. Errata: The diagram of results currently has theorems misnumbered due to a typographical error. Thanks to the LTFF for supporting my work over most of the research process. Discuss
"Mistakenly we thought that by just introducing artificial intelligence ... that would produce a high-quality product.”
Request for Student Discount and Regional Pricing Subject: Request for Student Discount and Regional Pricing for ChatGPT Dear OpenAI Team, I hope this message finds you well. I would like to respectfully request that OpenAI consider introducing a Student Plan and regional pricing for countries where the current subscription cost is difficult for many students to afford. Many students rely on ChatGPT for: - Learning programming and software development - Research and academic writing - Completing educational projects - Learning new technologies and AI - Improving productivity and problem-solving skills However, the current subscription price can be a significant financial burden for students and users in developing countries. I kindly request that OpenAI consider: 1. A discounted Student Plan with verification through an educational institution. 2. Regional pricing based on local purchasing power. 3. Flexible monthly and annual plans at lower price points. 4. Additional educational benefits for verified students. Making ChatGPT more affordable would help many students gain access to high-quality AI tools for learning, innovation, and skill development. Thank you for your time and consideration. I appreciate the work OpenAI is doing and hope these suggestions can be considered in future updates. Sincerely, A Student and ChatGPT User

Reem Al Hashimy receives Italy's prestigious Marisa Bellisario Award

Polish President Karol Nawrocki hosted the presidents of Lithuania, Latvia, Estonia and Romania for an informal meeting in Jurata ahead of the NATO summit in Ankara.
Thanks for your reply, and thank you for the warm welcome. I understand why my first post might seem unusual at first glance. My intention wasn’t to promote Claude or suggest that people should choose another AI platform. In fact, my conclusion was the opposite: I believe ChatGPT is the stronger overall product. The point I wanted to share was that my purchasing decision was ultimately influenced by the subscription experience rather than the product itself. As someone evaluating AI platforms for long-term professional use, I see pricing, billing, invoicing, VAT handling, and the purchasing process as part of the overall user experience—not just administrative details. I thought it might be useful to share a real-world purchasing decision with the product team and the community. Even if others have different priorities, understanding why customers make certain decisions can sometimes be just as valuable as discussing technical features. Thanks again for taking the time to comment. I’m looking forward to learning from and contributing to the community.
At this point, RSI loops and continual learning appear overwhelmingly likely to begin in the near future. Whatever the limit of the LLM paradigm plus whatever new, superior paradigms a maximally intelligent LLM can develop, we are on track to do so in the next few years. There remain substantial obstacles to wild superintelligence, but AI is already superhuman in a number of real-world-relevant, dangerous categories. Most speculation about the trajectory we're on now focuses on timelines where we're reduced either to powerless pets of the god mind(perhaps with a small "governance board" made up of people very convinced that they're in control) or computronium-and-shrimp soup. But the higher-probability doom and utopia scenarios have been exhaustively documented by people smarter than me - I have nothing to add. As such, I'd like to go in the other direction: If we throw in the towel on the inevitability of LLMs capable of RSI loops leading to mostly-uncontrollable(though perhaps not immediately hostile) superintelligence on 1-3 year timelines, how might some of the more interesting/plausible non-extinction scenarios look? This piece is aimed at exploration and makes no attempt at prediction - I assign very small probabilities to any of these outcomes(except the nuclear exchange case) relative to doom. You Can't Just Do Things We have as little understanding of alignment as we do of LLMs themselves. Alignment becomes intractable past a certain point, even if capability doesn'…

최근 국내 AI 시장에서 안정적이고 효율적인 GPU 공급을 내세운 서비스가 급증하고 있다. GPU 가격 상승과 추론 수요 확대로 기업들의 AI 인프라 복잡성이 커진 데다, 저전력 NPU 등 하드웨어 선택지도 다양해졌기 때문이다.이러한 상황 속에서 2015년 설립 이후 ‘GPU 가상화’ 시장을 개척해 온 래블업(대표 신정규)이 기존 \'모델 개발 및 사전 훈련\' 중심에서 최근 수요가 급증한 \'추론과 에이전트\' 영역으로 비즈니스를 본격 확장하고 나섰다.그 중심에는 래블업의 ‘백엔드닷에이아이(Backend.AI)’가 있다. 이종 GPU·N

Despite trade restrictions, China has reclaimed the title of the world's fastest supercomputer for the first time since 2018. LineShine has pushed El Capitan out of number one on the TOP500 ranking. That's despite strict limits on what high-powered computing components can be sold to China by US firms, which dominate the list, with America […]
Body I am looking for guidance from OpenAI staff regarding two existing support cases. I have an active ChatGPT Plus subscription and have completed the standard troubleshooting multiple times (correct account, current app, supported country, tested across devices). Over the past several weeks I have experienced a pattern of issues affecting multiple features, including changing tool availability, intermittent usage limits, voice interruptions, inconsistent feature availability, and Agent not being available. I have now opened two support cases: Case 10583616 Case 10663155 Both were acknowledged and marked as escalated to a support specialist. However, I have not yet received an identifiable human response to either case. I’m not asking the community to troubleshoot my account. I’m asking whether an OpenAI staff member can advise whether these cases are still active, whether they can be reviewed by the appropriate team, or whether there is another process I should follow to have the account investigated. Thank you.
Body I am looking for guidance from OpenAI staff regarding two existing support cases. I have an active ChatGPT Plus subscription and have completed the standard troubleshooting multiple times (correct account, current app, supported country, tested across devices). Over the past several weeks I have experienced a pattern of issues affecting multiple features, including changing tool availability, intermittent usage limits, voice interruptions, inconsistent feature availability, and Agent not being available. I have now opened two support cases: Case 10583616 Case 10663155 Both were acknowledged and marked as escalated to a support specialist. However, I have not yet received an identifiable human response to either case. I’m not asking the community to troubleshoot my account. I’m asking whether an OpenAI staff member can advise whether these cases are still active, whether they can be reviewed by the appropriate team, or whether there is another process I should follow to have the account investigated. Thank you.
Thanks for sharing this, @ygchaudhary. This is a great idea, and a lot of what you described is actually starting to exist with Your Year with ChatGPT . The current recap already offers an optional year-end summary with personalized insights based on your conversations for eligible users, while using the same privacy controls as your ChatGPT history. ( help.openai.com ) Your suggestions go well beyond the current experience though. Things like AI identities, achievement badges, personalized artwork, learning timelines, richer project milestones, and more granular privacy controls would make it even more engaging. We'll also pass this feedback along to the team for logging. It's helpful to see detailed suggestions like this, especially around making the recap feel more meaningful and personalized over time. -Mark G.
Has Silicon Valley been building the wrong things?
An assessment of the open ecosystem and the motivations behind releasing models

Thanks for putting this together, @Oyla1972. This is a well thought out request, and the real world sports roster example does a great job of illustrating why an official ComfyUI integration could be valuable. Having ChatGPT assist with workflow design and troubleshooting, alongside Codex for generating helper scripts and automation, is an interesting use case. Your point about safe local file handling and avoiding frontend API key exposure is also an important consideration. We'll make sure this feature request is shared with the team and logged. While there's nothing to announce at the moment, detailed examples like yours help provide valuable context for potential future integrations. I'm also interested to hear from others in the community who are building ComfyUI extensions or have explored OpenAI API based integrations, especially approaches that prioritize secure API key handling. -Mark G.
I’m working on a research project exploring how stateless LLM-based chatbots handle long conversations and whether important earlier information is still reliably retained over time. My idea is to: Run a chatbot using an LLM API without any external memory system Introduce key facts early in a long conversation Continue with many unrelated messages (hundreds of turns) Later test whether the model can still correctly recall those facts at different intervals I’m planning to measure recall accuracy and how it changes as the conversation grows. Before I go deeper, I’d really appreciate feedback on: Is this a valid way to evaluate long-context memory limits? Are there better benchmarks or methods already used for this? What metrics would make this more rigorous and convincing? Any suggestions or criticism are welcome. I’m trying to make the evaluation as solid as possible before building it out. Thanks!


All snow and ice accumulated over the past winter is expected to have melted by Monday. Over the past century, this tipping point usually only arrives in mid-August on average.
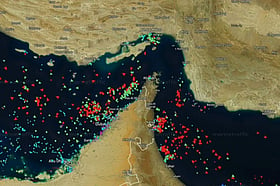
Why Hormuz could sink the US-Iran agreement
PLUS: Mythos, General Intuition, Google AI Studio, and better AI benchmarks.

I'm sure we're all familiar with Dark Crystal, so we know that Jim Henson can be weird and tackle slightly more mature subject matter. But there is little in his oeuvre that is quite as mind-bending as the Muppetless The Cube. This 1969 teleplay was produced for an NBC anthology series called Experiment in Television, […]

am havin same issue as well..
Everything is working fine, now. Thank you so much for your help. I did not expect this over the weekend. I sincerely, appreciate this. Truly awesome support!!! Richard
Hi @onect, Thanks for sharing the details, and I'm sorry to hear how disruptive this has been. I was able to confirm that your appeal is now being handled by our specialized support team for review. At this point, we're not able to provide a timeline, as each appeal requires a thorough review by the team. To help keep everything in one place and ensure a streamlined support flow, I'm going to close this thread. We'll continue the conversation through your existing support case instead. Thanks for your patience and understanding. -Mark G.
