Apply to IBM Quantum Developer Conference 2026
Get an exclusive look at the breakthroughs, tools, and workflows shaping the path to quantum advantage.
AI/ML news, top picks, and generated innovation digests.
6034 matching items
Get an exclusive look at the breakthroughs, tools, and workflows shaping the path to quantum advantage.
It’s time for our annual Fourth of July grill episode here at Decoder. This is when we invite the CEOs of outdoor cooking companies onto the show to explain just how their businesses kind of look like every other business. And this is a very special edition. Today I’m talking to Roger Dahle, the CEO […]
Comcast spent 25 years arguing that media and broadband belonged together. Now it's breaking them apart.
Fashion was a highlight of the 2026 BET Awards. Stars like Janet Jackson and Teyana Taylor arrived in statement outfits, while others missed the mark.

Despite an initially expected downturn, Deputy Tourism Minister Kostas Koumis said tourism in Cyprus had returned to a "stable course", adding that improving performance in recent months showed government measures had "a positive impact".

A few days ago I shared a project I’ve been working on called “LatentGate” — a local-first pipeline that reduces LLM API token usage by processing inputs before sending them to the model. After some great feedback, I’ve now turned it into: A pip-installable Python package A VS Code extension (runs as a local proxy) MCP server support for tools like Claude Code, Cursor, Cline, Continue PyPI → pip install latent-gate VS Code → LatentGate — Local-First AI Compression What it does Images (~1000–1300 tokens) → compressed to ~150 tokens using local vision models (Ollama + LLaVA) Long prompts / conversations → compressed locally before hitting cloud APIs Works with OpenAI / Claude / Gemini APIs Fully local preprocessing (no data leaves your machine before compression) The idea is inspired by VL-JEPA — predicting in embedding space, then decoding selectively. Why I built this While experimenting with GPT-4o / vision APIs, I noticed most costs come from raw input size (especially images and long prompts). So instead of optimizing prompts endlessly, I tried: → “What if we reduce what we send in the first place?” What I’m looking for I’d love feedback from this community, especially: Edge cases where compression breaks context Cases where output quality drops noticeably Prompt / API compatibility issues (OpenAI especially) Performance bottlenecks Better approaches to selective decoding or compression If you try it and something fails — that’s honestly the most valuable thing for me rig…
Rocket Lab, the space company best known for its small satellite launcher Electron, has announced plans to acquire Iridium Communications for $8 billion. The deal will combine Rocket Lab's launch services and spacecraft manufacturing with Iridium's satellite-based communications network, putting it in a better position to challenge SpaceX. Iridium offers communications services to over 2.5 […]
Hours after Absa Bank Kenya announced the departure of chief executive Abdi Mohamed after a 32-year career at the lender, rival I&M Group named him as the next CEO of its Kenyan banking business.
Labour's likely next PM set out a 10-year economic plan in his Manchester speech, promising greater regional powers and a shift away from trickle-down economics.

The Strawberry Moon rises over Europe this evening, bringing with it centuries of tradition and absolutely no strawberry colouring whatsoever.

Swiss engineering startup Subatron has obtained €162,000 (CHF 150,000) from Venture Kick to develop a new generation of underwater communication technology. The solution aims to enable faster, more r...

You don't need Mythos or GPT-5.5-Cyber to find a vuln to exploit when the world's password habits are so sloppy
Excellent breakdown of SRPO and its impact on AI reasoning. The emergence of self-verification and structured thinking is particularly impressive. These advancements could significantly improve the effectiveness of a href="mathssolverai.com">many problem-solving tools and intelligent applications. Thanks for sharing this insightful research.

I've come across a situation that I haven't had to deal with before and I've reached an impasse. Problem Patients in a health system are routinely monitored for a lab value important for diabetes management (A1c). When A1c reaches a particular level (higher than normal) a nurse reaches out to the patient to discuss medication and other proper treatment strategies. There is no natural control group, but we have A1c values for all patients over a number of months prior to the contact and after the contact. We would like to test the hypothesis that the intervention positively affects A1c (brings it down toward normal). My thoughts Initially, I thought that an interrupted time series would work since this intervention started at a particular calendar date, and we have information about the entire cohort. However, individuals were contacted over a 2-year period, so this will not work. Then, I thought that longitudinal modeling, with some kind of linear spline function. However, I'm concerned about the fact that enrollment / inclusion in the study (intervention) is based on the outcome. There is also substantial autocorrelation in each patient's series. While there is no natural control group, one could use individuals for whom contact was attempted, but did not engage. I'd imagine that some kind of propensity score would be needed in that case. Any citations or suggestions are appreciated.
ive also been experiencing the same issue with both 5.5,5.4 and 5.4 mini

Scientists in Norway have found that exclusively breastfed babies are less likely to develop ADHD symptoms, with girls showing the strongest benefits.

Healthcare startup MyKare.ai has raised $3.2 million, including an additional $1 million in Series A funding round. The round saw participation from Andrew and Alfredo, founders of Papa.com, and a leading family office from the Middle East. The fresh funds will be used to enhance AI capabilities, accelerate product development, and support global expansion, MyKare said in a press release. Co-founded in 2021 by Senu Sam, Rahmathulla T M, and Joash Philipose, MyKare.ai develops an AI native healthcare operating system for clinics and hospitals. Its platform helps automate patient acquisition, appointment booking, follow ups, communication, feedback collection, and other administrative workflows through AI agents and voice AI. The startup aims to improve operational efficiency and patient experience by integrating these functions into a single platform. Its AI agents can also manage patient queries, identify intent, answer calls, update CRM records, and support patient retention. According to the company, it serves healthcare organizations across India, the Middle East, the United Kingdom, and the United States. It directly competes with the other notable players in this space such as Yellow.ai, Haptik, Senseforth.ai, Hyro, and Cognigy.
Feature request Please add a reading / focus mode in the ChatGPT mobile app that lets users temporarily hide persistent on-screen UI while reading long responses. Problem When reading a long ChatGPT response on mobile, the persistent app UI takes up a significant amount of vertical screen space. On my device, the header, input area, and related controls occupy more than 20% of the visible screen . That is workable while composing a message, but it becomes a problem once the user’s intent shifts from writing to reading . For long-form answers, research summaries, code explanations, writing drafts, planning output, or step-by-step instructions, the current mobile UI makes the response feel cramped and forces substantially more scrolling than necessary. The issue is not that these UI elements persist in most cases – the issue is that there is currently no way to temporarily dismiss them when the user is reading, or otherwise has a reason to. Expected behavior ChatGPT could support a mobile reading pattern where non-essential UI can be hidden while the user is consuming long-form content. There are many apps that already employ straight-forward approaches to this that users would already expect and be familiar with, requiring no acclimation or adjustment. Any of these interaction models would fit common user mental models: Auto-hide on scroll: Hide the header and/or input area when the user scrolls down through a response, then restore them when the user scrolls up. Menu option:…
Holocene is not trying to build the next billion-dollar climate company in Africa but is trying to build several worth $30 to $50 million each and sell them within three to five years.

Anti-immigration protestors are demanding the removal of undocumented migrants and tighter border enforcement, setting their own deadline of June 30.

The 33+ unauthenticated API endpoints in the entity responsible for RBI's bank.in domain registry exposed 5000 bank employees' sensitive data, like password hashes, login IPs, for 13 months. The post Explained: How vulnerabilities in RBI’s bank.in registry exposed sensitive data for 13 months appeared first on MEDIANAMA .
Fun with API calls , as long as nobody is documenting gpt-image-2, nor noting overbilling reports nor fixes, seen above or elsewhere (such as on gpt-5.2 model vision): Send 23 input images to gpt-image-2 Why should I stop you? === 2026-06-29 05:42:54 | Images API request (edit) === (JSON-like approximation; actual call is http multipart/form-data) { "model": "gpt-image-2", "prompt": "Give the tall model the yellow baby doll dress seen in the other images", "size": "480x1408", "output_format": "png", "quality": "low", "background": "opaque", "n": 1, "image": [ "METADATA - filename: image.png; bytes: 933314; dimensions: 480x1408", "METADATA - filename: image2.png; bytes: 2400332; dimensions: 1536x1024", "METADATA - filename: image3.png; bytes: 2439315; dimensions: 1536x1024", "METADATA - filename: image4.png; bytes: 1688169; dimensions: 1536x1024", "METADATA - filename: image5.png; bytes: 2291162; dimensions: 1637x928", "METADATA - filename: image6.png; bytes: 2320081; dimensions: 1637x928", "METADATA - filename: image7.png; bytes: 2006693; dimensions: 1600x960", "METADATA - filename: image8.png; bytes: 815813; dimensions: 480x1408", "METADATA - filename: image9.png; bytes: 920722; dimensions: 480x1408", "METADATA - filename: image10.png; bytes: 1450837; dimensions: 1024x1024", "METADATA - filename: image11.png; bytes: 1694557; dimensions: 1024x1024", "METADATA - filename: image12.png; bytes: 935225; dimensions: 480x1408", "METADATA - filename: image13.png; bytes: 863611; dime…
Thermal cameras have saved me thousands over the years. Just the other day, one simple check saved me $1,000.

I think that you’re a bit too strong in your approach. I know that on my end, codex that has really strict quota is only focusing on doing his job without the “human like” feedback. But on GPT that transform codex feedback to “non professional coder” to me, I’m happy to have him introduce some emotions in the feedback.

Always impressed with the depth of your posts. You cover topics thoroughly. www.twohillsseptic.ca
Since the new ChatGPT 5.5 Instant model was released last week, we’ve seen issues with ChatGPT Instant not reliably completing App/MCP tool flows. Observed behavior: ChatGPT Instant either does not call any available tool, or calls only the first tool in the flow. After that single call, it stops and says it does not have access to the other tools, even though those tools are available. In our experiments, when ChatGPT Free usage falls back from Instant to ChatGPT Mini, the same tool flow starts working again. The flow also works as expected when using Thinking or Auto modes. This suggests the new Instant mode may not be invoking the follow-up tool calls required to complete a user request. Expected behavior: When a user asks ChatGPT to complete a task that requires tools, ChatGPT should continue calling the available tools as needed until the request is complete, rather than claiming it lacks access or stopping after the first tool call. Has anyone else observed this with ChatGPT 5.5 Instant and multi-step App/MCP tool flows? Happy to share reproduction details if helpful.
The Beef Case at Papi Steak, the buzziest restaurant at the Fontainebleau Las Vegas, is delivered in a diamond briefcase and comes with a full show.
Pocket sells a $129 credit card-shaped puck, which sticks to the back of your phone, and promises unlimited recordings, transcriptions, and to-do items.
Sony's Bravia 8 II might be a generation behind, but it still offers plenty of reasons to buy - especially with this discount.


106-hour miracle: Man rescued from quake rubble
Unnecessary characters, replacing the main star, and adding ridiculous plots are just some of the signs that it's time to call it quits.
Germany has most jobs at risk while Luxembourg has largest share in occupations that may actually grow with AI, firm says in new report.

British American Tobacco is cutting 5,500 jobs across the globe and handing thousands more roles to outside contractors, as the cigarette giant races to strip out costs and pivot towards vapes and nicotine pouches.

A unibrow, flowers, bold colours — Frida Kahlo’s image is known around the world. Tate Modern’s record-breaking new exhibition brings together more than 30 works by the Mexican artist, alongside pieces by those she inspired.
Joanna Stern says her experiment with AI reinforced the importance of human relationships, skepticism, and real-world experiences.
With all of its operating ecosystems now profitable, Prosus is seeking to prove that its own businesses can generate sustainable earnings and stand on their own.
This post was created in partnership with Adobe Brand discovery has always happened in places companies don’t fully control. What’s different now is that the intermediary doesn’t just surface options. […]
This post was created in partnership with EightPM Consumers aren’t just avoiding ads—they’re choosing content that feels worth their time. To earn that attention, brands have to show up inside […]
This post was created in partnership with Sam’s Club Retail media that looks beyond ROAS and leverages customer insights can unlock long-term value and customer loyalty. During an ADWEEK House […]
An extraordinary Council of Ministers has extended economic measures against the global crisis, approved a new housing plan and updated macroeconomic forecasts for the state budget.

Today, you probably asked a question of a large language model, or accepted a connection suggestion on LinkedIn, or watched a recommended video on YouTube, or took a different route to work based on a traffic prediction from Google Maps. In other words, you probably used artificial intelligence. But what you might not know is how much energy that interaction consumed or why. AI requires processing massive amounts of data, which is usually done in large data centers populated by thousands of GPUs capable of executing up to trillions of operations per second. But each of those GPUs achieves that by consuming as much as 1,000 watts apiece. For comparison, if you’ve got a newer smartphone, it probably uses less than 1 W. That kilowatt figure puts GPUs on the same level as vacuum cleaners, dishwashers, and stoves, but with the big difference that data-center processors are operating uninterrupted around the clock. Fundamentally, a lot of this inefficiency is because GPUs are trying to simulate the workings of artificial neural networks using software and billions of transistors, which requires using energy to move massive amounts of data. What’s more, the simulated artificial neurons that make up these networks lack even a fraction of the complex computing behavior of the biological neurons that comprise the most energy-efficient computing system that we know, the human brain. The brain is roughly one million times as energy efficient at many of the comparable tasks we set for AI…
%20copy.jpg)
Flipper Devices, a company that built a banned hacking device, now wants to hack your attention span.
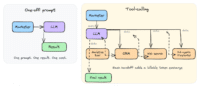
A single afternoon of tool-calling can eat a $20 monthly subscription. The fix isn't using fewer tools, it's changing where your data lives. The post Agentic AI is rewriting martech economics and infrastructure appeared first on MarTech .
Das "KI-Update" liefert drei mal pro Woche eine Zusammenfassung der wichtigsten KI-Entwicklungen.
Omen AI raised a $31 million Series A to monitor chip coolant and stop bacterial outbreaks in data centers.
The company's productivity-focused gadget helps you set timers, block apps, and display custom messages and widgets on an LED display.